
Decision Engineering in Lending: What Agentic AI Makes Visible
Before you deploy AI in lending, read this.

The Borrower the System Could Not See
Take the case of Alex, a self-employed consultant.
Five years of regular GST payments. Neatly maintained tax files. A growing list of clients with good receivables. Undoubtedly, Alex fits perfectly into the borrower category of every credit institution.
Alex seeks a mortgage loan.
The credit institution’s system does not have a borrower. All it has are bits and pieces of the whole person, the fragments.
KYC in the legacy portal. GST records kept in a PDF folder. Banking account information collected from another vendor, which uses data communication protocols that don’t match with those of the core banking system. Not all the data systems are interconnected with one another. Incomplete data comes through, and the credit algorithm does what it needs to with incomplete data.
It flags the application as “Incomplete.”
Three days of manual reconciliation by an underwriter who goes around looking for pieces of Alex. By the time he manages to collect all the pieces, Alex’s interest has been lost. Worse still, the automated decision-making system might already have marked the file for closure.
Alex’s application has been turned down. This is not because of any credit risks he might be having. No, it is because the institution could not even see him.
This is not a rare occurrence. This is the basic problem that most credit institutions around the world find themselves facing on a daily basis. It also finds its way in the numbers.
Re-work ratios are at 18%, while the rate of first-time approvals is about 52%. Informal borrowers manage to score only 35%. Again, not because of any additional risks. Because the institution failed to get a complete picture of the borrower.
The problem is not with the borrower. The problem is with the data architecture.

What Agentic AI Actually Does to the Problem
Looking at Alex’s case, the institution realizes that what needs to be done here is to use agentic AI for this process.
So, it deploys Agentic AI and brings in an autonomous underwriting agent.
Within minutes, the agent makes all the necessary assessments and finds the same information gap and comes to the same conclusion about rejecting Alex’s application – faster than ever before. This time, Alex is turned down even before the matter reaches any human hands. And no one knows how this decision was made.
But the institution did not solve the problem by deploying Agentic AI. It automated it.
This is what comes of executing before being ready.
Lending has been automated improperly.
There can be no insertion of intelligence into a fragmented environment and expect integrity to be generated.
The data layer is not ready to accept an agent. So, the agent takes on the fragmenting, amplifies the fragmenting, and makes it impossible to reverse the process through speed.
The problem is not intelligence. The problem is the sequence.
A Different Architecture
However, the sequence can be corrected before the agent even enters the picture. Not by models, not by layers of vendors. By architecture built upon an ugly truth: An autonomous agent will only perform as well as its surroundings enable it to.
Developed in November 2025 as intellectual property, it is known as the STAGE Agentic AI Framework.
It does not supplant anything that the institution is doing now. It is the preparation for the agent.
Alex’s institution gave its agent fragments. STAGE gives its agent a person.
In Alex’s case, it means the opportunity for redemption - decision-making based on a complete view of him, not his pieces. In the institutional setting, it implies decision-making that is explainable and defensible.
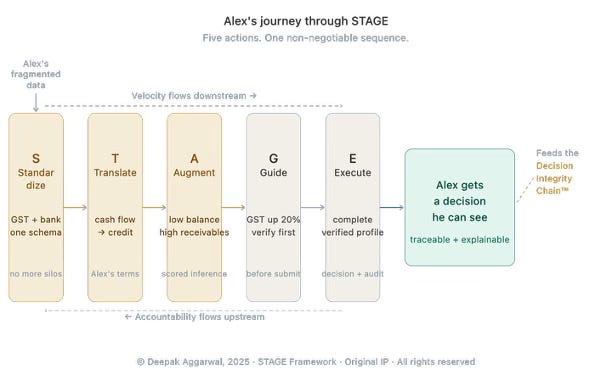
The standardization agent comes first, bringing all the information about Alex in line. GST, bank statements, and KYC information are unified into a common format. Alex’s entire information set has been pulled together in one place, and it has been translated into one language.
Next comes the translation agent, which translates the standardized information into meaningful financial intelligence - bank statements turn into transaction types; GST into debt/income ratios.
Where the value comes into play is in what STAGE delivers next.
An augmentation agent discovers an aspect of information that the initial model didn’t know about. Alex’s current bank balance is small, which is why the initial model identified a risk. However, his accounts receivable have been steadily increasing. This inference gets a confidence rating attached to it by the agent. Now the model knows everything it knows and just how confident it is about each discovery.
Even before anything goes into the execution process, a guidance agent brings up a particular prompt to the underwriter - Alex doesn’t have his tax records from 2024, but he saw a 20% increase in his GST for the same year.
Verify and move forward? Underwriter verifies. And all of this occurs upstream of the decision-making process.
That is when the execution agent takes action, based on a fully vetted and accurate profile of a borrower who has been seen in its full personhood from the outset of the process.
Alex is approved.
What Changes When the Sequence Is Right
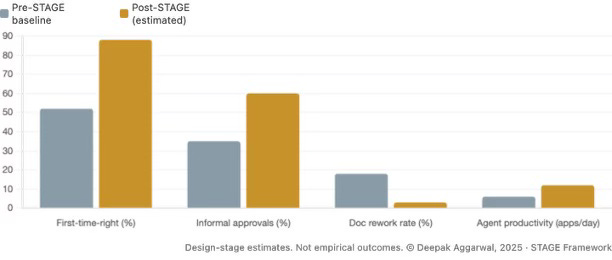
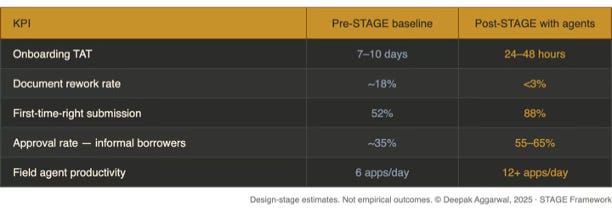
The problem wasn’t the model. The problem wasn’t even the algorithm. Alex’s data had been there all along. What changed was the order in which that data was processed and prepared for the decision. Process it correctly, and it takes you down from seven to ten days to onboard in twenty-four to forty-eight hours. Rework rates go from around 18% down to 3%. First-time-right goes up from 52% to around 88%. Informal borrower approvals - such as Alex’s - jump from 35% to 55% to 65%.
This isn’t about having a better model. It’s about having the correct process.
Decision Engineering™ and the Governance Imperative
This is Decision Engineering™.
Loan decisions are not model outputs. Loan decisions are transformation processes that take data on the borrower from raw information through standardization, translation, augmentation, guided correction, and finally to execution. If those transformations can’t be tracked back through the system, your organization has already breached the Fiduciary Gap - the fundamental gap between what it is optimized for and what it is obligated to protect. Alex’s rejection was not the result of a bad model. It was the Fiduciary Gap in action.
Without being able to trace the chain, there can be no governance. Nothing but educated guesses on a massive scale.
For the majority of institutions, that chain fails when it comes to the data layer. Meaning that information is faulty, reasoning is hidden, and any decision-making can only be justified by reconstructing what took place.
Reconstruction is not governance.
However, once you have established your sequence, something changes. Decisions become traceable from the instant that they were made. Each stage becomes visible. Every conclusion has an inherent degree of confidence attached. Each result can be accounted for without having to recreate what transpired.
Not only is it faster. It is Decision Velocity - the ability of an institution to shrink the time interval between input signals and actions while maintaining the mandate integrity needed to justify that decision.
With MAS, RBI, and the ECB all heading towards decision-level explainability, ungoverned velocity is the only version of speed allowed to scale.
The Decision Integrity Chain™, which consists of eight layers that bridge Purpose, Strategy, Intent, Rules, Judgment, Decision, Outcome, and Feedback, is what enables this traceability. STAGE acts on the data preparation layer that is required for the Chain to function. Without it, there would be nothing clean to feed into the Chain.
The Question Worth Asking
For any institution considering an investment in agentic AI systems, the question is clear-cut. What model should we implement?
However, that is not the question that needs to be asked.
The real question is simple. Is it possible to track Alex’s data from when it came into the system all the way until the end, one step at a time, and see if it holds up?
And if it cannot be done, it is not a problem with the model but with the ground floor.
That is precisely why STAGE was designed. The conversation is open.
If you are currently going through such an issue within your institution - fragmented data, ineffective deployment of agentic AI systems, or even governance gaps that you do not know how to justify to the regulator, and want to discuss how STAGE can be useful to your case, get in touch at deepakondecisions.substack.com or SSRN.
A word about the data
Operational KPIs referred to above — document remediation ratios, first-pass ratios, informal borrower approval ratios, and the before and after effects — are estimations created using the design technique outlined in the STAGE Framework (Deepak Aggarwal, November 2025). These numbers are based on current practices in the industry concerning loan operations in developing and developed countries, AI-based document processing and underwriting use cases, and research on the friction caused by data silos in the credit lifecycle. STAGE Framework has not been deployed in its entirety. This is only an estimation, not based on a live implementation of the framework.
A note on the frameworks mentioned
The Fiduciary Gap, Decision Velocity, Decision Engineering™, and the Decision Integrity Chain™ are concepts created by the author and published via SSRN. Those who want to know more about the theory behind these frameworks will find the work at ssrn.com/author=9450612.
STAGE Framework is proprietary IP owned by the author. Decision Integrity Chain™, DIC™, and DIC ChainTrace™ are trademarks of Deepak Aggarwal. © Deepak Aggarwal, 2025.
This is a familiar financial services failure.
The borrower looks fragmented because the institution is fragmented. In lending, context matters as much as data. Until banks connect the full customer picture across systems, good borrowers will keep getting treated like incomplete files, and underwriters will keep wasting time reconstructing what should already be visible.
So, the problem indeed is the data architecture.